41. évfolyam, 1995. 2. szám
| 41. évfolyam, 1995. 2. szám |
Archívum |
A nemzeti adatcsere formátum és az összevont adatelemek
OSZK Fejlesztési Osztály
Bevezető
Viszontválaszában Bakonyi Géza megismételte azt javaslatát,
hogy a HUNMARC nemzeti adatcsere formátumban bizonyos adatelemeket nem a szabvány
szerint elkülönítve kellene kezelni, hanem össze kellene vonni. Korábban már
megírtuk (A könyvtár nem ellentéte az elektronikus könyvtárnak. Válasz Bakonyi
Gézának. In: Könyvtári Figyelő, 5. (41.)évf. 1995. 1.sz. pp. 13-19.), hogy amikor
a nemzeti adatcsere formátum tervezetét a múlt évben vitára bocsátottuk, senki
sem tett ilyen jellegű módosító javaslatot. Bizonyára azért, mert akik a kérdéssel
foglalkoztak, feltételezték, hogy a nemzeti és nemzetközi adatcsere formátumoknak
meg kell felelniök az érvényes bibliográfiai szabványoknak. Márpedig, ha a HUNMARC
formátumban összevontan kezelnének adatelemeket, akkor a HUNMARC se a szabványoknak,
se a nemzetközi adatcsere formátumoknak nem felelne meg.
Az adatelemek elkülönített, minősített kezelése egyébként sem akadálya annak,
hogy a HUNMARC-ot használó könyvtárak a szabványos bibliográfiai megjelenítési
formátum mellett a szükségleteik szerinti egyéb, adott esetben rövidített megjelenítési
formátumokat is használjanak.
Részletes és táblázatban összefoglalt példa segítségével fogjuk bizonyítani,
hogy az adatelemeket nem a nemzeti csereformátumban kell összevontan kezelni,
hanem az egyszerűsítést, összevonást igénylő könyvtárak adatbázis-kezelő rendszerében.
Konvertálási példa négy könyvtárral
Vegyük példaként a HUNMARC 245-ös hívójelű "Cím és
szerzőségi közlés" mezőjének szabványos adatelemei közül az első hatot, melyeket
a továbbiakban a hívójel és az almezők betűjelével azonosítunk (pl. "245a
Főcím, ill. összetett cím közös része", "245b Alcím").
Tételezzünk fel négy, A, B, C és D jelű magyar könyvtárat
a következő jellemzőkkel:
1. Az A jelű könyvtár teljes részletességgel, azaz külön-külön minősítve
veszi át a fenti adatelemeket, de belső használatban, saját online és egyéb
katalógusában csak a "245a Főcím, ill. összetett cím közös része", valamint
a "245c Első elsődleges szerzőségi közlés" adatelemeket óhajtja megjeleníteni.
2. A B és a C jelű könyvtár összevontan akarja a fenti adatelemeket
átvenni, ugyanakkor mindegyik átvett adatelemet meg akarja jeleníteni.
3. A D jelű könyvtár összevontan és csak a 245a, valamint a 245c
adatelemeket akarja átvenni és megjeleníteni.
|
HUNMARC mezóhívójel |
HUNMARC Almezőjel |
Szabványos megnevezés |
A Könyvtár adatelemei |
B Könyvtár adatelemei |
C Könyvtár adatelemei |
D Könyvtár adatelemei |
|
245 |
a |
Főcím, ill. összetett cím közös része |
AE1 |
BE1 |
CE1 |
DE1 |
|
245 |
A |
Párhuzamps cím, ill, összetett. párhuzamos cím közös cím része |
[AE2] |
_=_ |
_=_ |
|
|
245 |
b |
Alcím |
[AE3] |
_:_ |
_:_ |
|
|
245 |
B |
párhuzamos alcím |
[AE4] |
_=_ |
_=_ |
|
|
245 |
c |
Első elsődleges szerzőségi közlés |
[AE5] |
_/_ |
_/_ |
_/_ |
|
245 |
e |
Második és minden további elsődleges szerzőségi közlés |
[AE6] |
_;_ |
_;_ |
|
Tételezzük továbbá fel az egyszerűen szemléltethető konverzió
érdekében, hogy minden adatelemnek van az adatcsere alkalmával értéke.
(Ha nem ebből indulnánk ki, nem lenne mit összevonni.)
Az egyes könyvtárak más-más módon azonosíthatják ugyanazt az adatelemet, illetve
az összevonás eredményeként keletkezett adatelemeket.
Az A jelű könyvtár például AE1-gyel, [AE2]vel stb. azonosítja
a HUNMARC szerinti 245a, 245A stb. adatelemeket (szögletes zárójelek
között azok az adatelemek szerepelnek, melyek megjelenítését, adott esetben
akár átvételét is a könyvtárban szükségtelennek ítélik).
A B jelű könyvtár BE1-gyel azonosítja a HUNMARC szerinti 245a,
245A, 245b, 245B, 245c és 245e adatelemek
összevonásából keletkezett adatelemét stb.
Az összevonások esetén az egyetlen mezőbe kerülő különböző adatelemek közötti
elválasztó jeleket is létre kell hozni a BE1, a CE1, illetve a
DE1 mezőkben (pl. köz : köz elválasztó jellel jelölve
az alcímet, köz / köz elválasztó jellel jelölve az első szerzőségi közlést).
Azt nem feltételezzük, hogy a Bakonyi Géza által említett "összevont kezelés"
egyben a "leírás adatcsoportjait elkülönítő, illetve adatelemeit megelőző kötelező
jelek" elhagyását is jelenthetné, hiszen ez ellentétes lenne a szabványokkal
(példánkban v.ö. MSZ 342411 3.2.3). Az A jelű könyvtár esetén viszont
nem az AE1 és az AE5 mezőkben kell létrehozni az elválasztó
jeleket (hanem azok között), mert azokat az adatbáziskezelő rendszer
tudja szükség szerint megjeleníteni, hiszen a könyvtárban a mezőket nem összevontan,
hanem elkülönítetten kezelik.
Az elmondottakat az alábbi táblázatban foglaltuk össze. (Az A jelű könyvtárnál,
amely nem von össze, az adatelemek kockáiban a szimbolikus adatelem-azonosítókat
tüntettük föl. Azoknál a könyvtáraknál, ahol összevonnak, az adatelemek kockáiban
az elválasztó jeleket tüntettük föl, melyeket a tárolt adatelemértékeken belül
elkerülhetetlenül létre kell hozni ahhoz, hogy megjelenítéskor az összevont
adatelemértékeket elkülöníthessék. Az át nem vett adatelemek kockáit - a D jelű
könyvtár esete - üresen hagytuk. A közt az aláhúzás jelével jelöltük.)
A példa elemzése
Látható, hogy az A jelű könyvtár esetén nincs összevonás,
az egyes átvett adatelemek önálló AE1, [AE2] stb. almezőkbe kerülnek.
A saját online és egyéb katalógusban megjelenítendő két, AE1 és AE5
adatelem között az elválasztó jelet a mindenkori adatbázis-kezelő rendszer hozza
létre, az elválasztó jel tehát nem alkotja az adatelem értékének részét.
A mai könyvtári adatbázis-kezelő rendszerek iránt természetes követelmény, hogy
üzembehelyezésük alkalmával - de akár később is - meghatározza a felhasználó,
milyen elválasztó jeleket kíván használni az egyes megjelenítési formátumokhoz.
Látható továbbá, hogy a B és a C jelű könyvtárak az összevontan
átvett adatelemeket egyetlen mezőben, egyetlen adatelemként kezelik, és az elválasztó
jelek az egységként kezelt mezőben az adatelemérték részét alkotják, attól elválaszthatatlanok.
Látható végül, hogy a D jelű könyvtár esetén kevesebb összevontan átvett
adatelem van, de ezt is egyetlen adatelemként kezelik, és az egyetlen szükséges
"köz dőlt vonal köz" elválasztó jel az egységként kezelt mezőben ugyancsak
az adatelemérték részét alkotja, attól elválaszthatatlan.
Vegyük számba, milyen konvertáló programokra van szükségük az egyes könyvtáraknak:
Ez a könyvtár tehát minden, az adatcsere céljára HUNMARC formátumot használó könyvtárral oda-vissza képes adatcserére. Következésképpen tőle a B, C és D könyvtárak is átvehetnek adatokat a HUNMARC-on keresztül, tehát a már meglévő konvertáló programjukkal.
Fordítva a csere nem lehetséges: a HUNMARC-ba az összevont adattartalmú BE1, illetve CE1 mezők értékei nem vehetők át egyszerű konverziós módszerekkel. (Egyszerű konverziós programokon kívül készíthetők bonyolultabb, ún. formátumfelismerő programok (formai recognition programs). Ha az összevonások egy-egy adatcsoporton belül maradnak, akkor ezek a programok az egyszerű eseteket konvertálni tudják, de a speciális eseteket nem: ezekben szellemi beavatkozásra van szükség, tehát a konvertálás eleve nem teljesen automatikus. Ha azonban több adatcsoportot is összevonnak, gyakorlatilag lehetetlen a konvertálás, mivel a szabványos bibliográfiai elválasztó jelek homonimák: ugyanaz az elválasztó jel más-más adatelemek között ismétlődhet (például a köz : köz a főcímet az alcímtől, a párhuzamos címet a párhuzamos alcímtől, a megjelenési helyet a kiadótól stb. választja el.)
Ez a két könyvtár tehát minden, HUNMARC formátumot használó könyvtártól át tud venni adatokat, de fordítva ez nem lehetséges.
Ez a két program biztosítja, hogy a B jelű könyvtár BE1 adatelemét a C jelű könyvtár a maga CE1 mezőjébe átvegye és fordítva.
A csere fordítva nem lehetséges: a HUNMARC-ba az összevont adattartalmú DE1 mező értéke nem vehető át egyszerű konverziós módszerekkel. Ugyancsak lehetetlen a csere egyszerű konverziós eszközökkel az A, a B és a C jelű könyvtárakkal.
Következtetések
A fentiekből szükségszerűen az alábbiak következnek;
a) Az adatcseréhez - függetlenül attól, milyen a HUNMARC - minden könyvtárnak
konverziós programokra van szüksége.
b) Az A jelű könyvtár oda-vissza tud cserélni adatokat minden olyan felhasználóval,
amelyik maga is minősítve, tehát nem összevontan kezeli a HUNMARC adatelemeit.
A HUNMARC-on keresztül át tud adni adatokat mind a B, C és D
jelű könyvtáraknak. Fordítva nem: a B, C és D jelű könyvtáraktól
egyszerű konverziós módszerekkel nem tud átvenni adatokat.
| Csak két (a csereformátumról és a csereformátumra)
konvertáló programra van szüksége. A HUNMARC-on keresztüli országon belüli és nemzetközi adatcserében kötetlenül részt vehet, saját maga azt használ fel amit és ahogy akar. |
c) A B és a C jelű könyvtár csak egymás között tud adatokat cserélni. Az OSZK-tól és az A jelű könyvtártól csak átvenni tud adatokat, saját adatait az OSZK-nak és az A jelű könyvtárnak egyszerű konverziós módszerekkel nem tudja átadni.
| Három konverziós programra van szüksége: az egyikkel
átveszi a HUNMARC formátumban az adatokat, a másik kettővel pedig egymástól
veszi át, illetve adja át az adatokat. Az országon belüli cserében csak azokkal a könyvtárakkal vehet részt, melyek maguk is pontosan úgy vonják össze az adatelemeiket. A HUNMARC-on keresztüli és nemzetközi adatcseréből kizárta magát. |
d) A D jelű könyvtár csak HUNMARC formátumban tud átvenni adatokat az OSZK-tól és az A jelű könyvtártól. Se a B, se a C jelű könyvtártól nem tud átvenni adatokat, és saját adatait egyetlen más könyvtárnak sem tudja egyszerű konverziós módszerekkel átadni.
|
Egyetlen konverziós programra van szükséges. Az országos és nemzetközi cseréből kizárta magát. |
A fentiekből világosan látható, hogy mind logikailag, mind
a cserélési szabadság, mind pedig a gazdaságosság szempontjából a legjobb helyzetben
az A jelű könyvtárak vannak. Ezek a könyvtárak nem úgy oldják meg azt
a problémájukat, hogy bizonyos adatelemekkel nem kívánnak foglalkozni, illetve
bizonyos adatelemeket nem kívánnak minősítve megjeleníteni, hogy összevonják
őket egyetlen - szabványosan nem létező adatelembe, hanem úgy, hogy az adatelemek
szelektív kezelését saját adatbázis-kezelő programrendszerükre bízzák, nem pedig
a csereformátumból konvertáló programjaikra.
Az is világosan látható, hogy a B, C és D könyvtárak helyzete
rendkívül hátrányos. Különösen az, ha meggondoljuk, hogy az általuk kezelt adatok
egy részében az elválasztó jelek az adatelemhez kötött értékeket képviselnek.
Ennek következtében a különböző felhasználói igények szerint kialakítandó megjelenítési
formátumokban nincs módjuk automatizált eszközökkel (tehát a saját adatbázis-kezelő
rendszerükkel) különféleképpen megjeleníteni az adatokat.
Ahhoz, hogy az OSZK-n kívül minden más könyvtár egymás között adatokat cserélhessen,
és ezt ne a "túl részletes" HUNMARC formátum szerint csinálja, arra lenne szükség,
hogy minden könyvtárat arra kényszerítsenek, hogy összevontan kezeljen
bizonyos adatelemeket, ezt az összevonást mindig egyformán végezzék el, tekintet
nélkül az érvényes nemzeti és nemzetközi szabványokra, az adott könyvtár speciális
igényeire és az esetleges időbeli változásokra. Eme összevonás következtében
- ha egyáltalán rákényszeríthető erre központi erőszak nélkül bármely könyvtár
- egyetlen könyvtár sem lehetne abban a helyzetben, hogy a HUNMARC-on keresztül
az OSZK-val és bármely más, külföldi könyvtárral adatokat oda-vissza cseréljen.
Gyakorlati példa
Az egyszerűség kedvéért csak a bibliográfiai leírás részletét, a cím és szerzőségi közlés adatcsoportot mutatjuk be. A szemléltethetőség érdekében a csereformátum mutatójában szereplő hívójelet rendeljük hozzá az adatelemhez azonosítóként, elhagyva az indikátorokat és az almező-azonosító típusjelét (vagyis az adatelemek azonosítását a tároláskor is leegyszerűsítve, a kiindulópontul választott eszközökkel jelezzük). Indikátorokkal és almező-azonosító típusjelével az első két adatelem például így festene:10$aMagyarország lombos erdői$bA tiszta levegő szűrői$ADie Laubwälder...A HUNMARC által szolgáltatott tételrészlet fentiek szerint végrehajtott "tárolása" és megjelenítése a következő:
(i) Tároláskor

Látható, hogy a HUNMARC nem tartalmazza az adatelemek közötti
szabványos bibliográfiai elválasztó jeleket. A könyvtári adatbázis-kezelő rendszerekben
az implementálás során meghatározható, hogy az adatelemek elé az egyes megjelenítési
formátumokban a minősítésük alapján milyen elválasztó jel kerüljön. Az így -
automatikusan - megjelenített elválasztó jelek nem részei az adatelemek adattartalmának.
Más szóval, különböző megjelenítési igényekhez, különféle módon, különféle elválasztó
jelekkel lehet a tételeket megjeleníteni. Például:
(ii) A szabványos bibliográfiai leírást tartalmazó megjelenítési formátum a
következő (az adatbázis-kezelő rendszer által megjelenített elválasztó jeleket
félkövér dőlt szedéssel, a közt az aláhúzás jelével jelöltük):
Magyarország lombos erdői_:_A tiszta levegő szűrői
_=_Die Laubwälder Ungarns_:_Filter der reinen
Luft_/_írta Kálózy István_;_fényképek Horváth Gyöngyvér
(iii) Ugyanez táblázatos megjelenítési formátumban például a következő lehet (az elválasztó jeleket itt is félkövér dőlt szedéssel jelöltük, a CR LF a soremelés kocsi vissza jelölése [hiszen az is az elválasztás jelölése, hogy valami új sor elején kezdődik]):
|
főcím: |
Magyarország lombos erdői |
CR LF |
|
Alcím: |
A tiszta levegő szűrői |
CR LF |
|
Párh. cím: |
Die Laubwälder Ungarns |
CR LF |
|
Párh. alcím: |
Filter der reinen Luft |
CR LF |
|
1, elsődl. szerzőség: |
írta Kálózy István |
CR LF |
|
2. elsődl. szerzőség: |
fényképek Horváth Gyöngyvér |
Az A) könyvtár mindegyik adatelemet átveszi és valamilyen módon tárolja a saját belső formátumában, de csak a főcímet és az első elsődleges szerzőségi közlést tünteti föl a saját online katalógusában, megőrizve az átvett adatelemek eltérő minősítését (azaz "nem von össze" adatelemeket).
(i)Tároláskor:

Az előbbiekben bemutatott két formátum pedig, melyekben csak a félkövéren szedett AE1 és AE5 adatelemeket jelenítik meg, a következő
(ii) Sorfolytonosan (az elválasztójelet a kezelőprogram írja ki):

(iii) Táblázatosan:
|
Cím: |
Magyarország lombos erdői |
CR LF |
|
Szerzőség: |
írta Kálózy István |
CR LF |
Akár megőrzi a könyvtár a későbbiekben a nem megjelenített
adatelemeket, akár nem őrzi meg, a példánkban megjelenített AE1 és AE5
adatelemek cseréje minden HUNMARC formátumot használó könyvtárral egyszerű konverziós
eszközökkel megvalósítható. A csere független attól, hogy melyik könyvtár milyen
elválasztó jeleket alkalmaz, mivel az elválasztó jelek nem részei az adattartalmaknak.
A B) és C) könyvtárak két mezőbe összevonva kezelik az
átvett adatelemeket. Náluk a tárolás és a két formátum a következő (a B könyvtár
BE1 adatelem azonosítását használva):
(i) Tároláskor:
Azaz, már eleve az elválasztó jelekkel együtt kell tárolni az adatelemeket, mert külön-külön lemondtak a minősítésről azáltal, hogy összevontan kezelik őket.
(ii) Sorfolytonosan:
|
Magyarország lombos erdői_:_A tiszta levegő
szűrői |
Mivel a sorfolytonos megjelenítéshez szükség volt elválasztó jelek megjelenítésére, és mert ezek az elválasztó jelek az összevonás következtében - tehát az egyes adatelemek minősített kezelésének hiányában - az adattartalom részét alkotják, ezért minden más megjelenítési formátumban, így a táblázatosban is meg kell hogy jelenjenek.
(iii) Táblázatosan:
| Főcím és szerzőség: | Magyarország lombos erdői_:_A tiszta levegő szűrői _=_Die Laubwälder Ungarns_:_Filter der reinen Luft_/_írta Kálózy István_;_fényképek Horváth Gyöngyvér |
A példánkban bemutatott
BE1 adatelem cseréje HUNMARC formátumát használó könyvtárral egyszerű
konverziós eszközökkel megvalósíthatatlan. A csere csak azokkal a könyvtárakkal
lehetséges, melyek ugyanilyen módon vonják össze a szabványos adatelemeket.
A példából jól látható ennek a módszernek a másik súlyos hátránya: többé nem
lehet szabadon formátumokat definiálni, hiszen az elválasztó jelek az összevont
adatelem adattartalmához tartoznak, attól már nem választhatók el, vele együtt
tárolják őket, s ezért minden más megjelenítéskor is meg kell hogy jelenjenek.
Persze külön speciális formátumfelismerő programmal és ezt elkerülhetetlenül
kiegészítő szellemi munkával az elválasztójeleket újra ki lehetne szűrni de
akkor meg minek volt az összevonás és minek kellett lemondani a differenciált
minősítésekről?
A D) könyvtárban is egyetlen mezőbe összevonva kezelik az átvett adatelmeket,
de csak két adatelemet vesznek át. Ebben a könyvtárban a tárolás és a két formátum
a következő:
(i) Tároláskor:
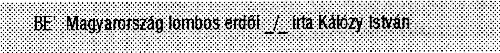
Tároláskor itt is eleve az elválasztó jelekkel együtt kell tárolni az átvett adatelemeket, mert külön-külön lemondtak a minősítésről azáltal, hogy összevontan kezelik őket.
(ii) Sorfolytonosan:
|
Mivel a sorfolytonos megjelenítéshez itt is szükség volt elválasztó jelek megjelenítésére, és mert ezek az elválasztó jelek az összevonás következtében - tehát az egyes adatelemek minősített kezelésének hiányában - itt is az adattartalom részét alkotják, ezért minden más megjelenítési formátumban, így a táblázatosban is meg kell hogy jelenjenek.
(iii) Táblázatosan:
| Főcím és szerzőség: | Magyarország lombos erdői_/_írta Kálózy István_;_fényképek Horváth Gyöngyvér |
Korábban már kifejtettük, hogy a DE1 adatelem cseréje
HUNMARC formátumot használó könyvtárral egyszerű konverziós eszközökkel ugyancsak
megvalósíthatatlan, és ebben a könyvtárban sem lehet többé szabadon formátumokat
definiálni.
Összefoglalva megállapítható, hogy ha
- valamelyik könyvtár kevesebb adatelemet akar megjeleníteni,
akkor
- kevesebb adatelemet vehet át a HUNMARC formátumon alapuló adatcserében,
vagy
- minden adatelemet átvesz, de csak az általa szükségesnek ítélteket használja
föl,
de
- semmiképpen se úgy járjon el, hogy összevontan kezeli azokat az adatelemeket,
melyek megjelenítésére igényt tart.
Az alternatívák összefoglalása
Az elfogulatlan olvasó levonhatja ezek után magának a következtetéseit:
milyen nemzeti adatcsere formátum felel meg a leginkább az érdekeinek?
Az olyan, amely bizonyos adatelemeket öszszevontan, nemzeti és nemzetközi szinten
nem csereszabatosan kezel és előre megköti a felhasználó kezét?
Vagy az olyan, amely minden adatelemtípust minősítve kezel, és a felhasználóra
bízza, mihez kezd velük?
![]()
| Országos Széchényi Könyvtár Észrevételek (2000/04/12) |