40. évfolyam, 1994. 3. szám
| 40. évfolyam, 1994. 3. szám |
Archívum |
Az információ mérése
Robert M.Hayes
A szerző Measurement of ínformation c. előadása a COLIS (Conceptíons of Library and Information Science) konferencián hangzott el 1991-ben Tamperében. A tömörítést Fülöp Géza készítette.
Bevezetés
A cikk az információmértékek problematikáját
tárgyalja a fogalom következő meghatározása alapján: az információ az adatoknak
(azaz rögzített szimbólumoknak) az a tulajdonsága, amely feldolgozásuk hatását
reprezentálja (és méri).
Tárgyalja az információ fogalmának és más releváns fogalmaknak a köznapi használatát,
méréselméletének történelmi fejlődését, s a még megoldatlan elméleti problémákat.
Az információ meghatározásában az adatok feldolgozása központi helyet foglal
el. A cikk a feldolgozás négy szintjét veszi figyelembe: 1. adatátvitel; 2.
adatszelektálás; 3. adatstrukturálás; 4. adatredukció. Minden szinthez meghatároz
egy mértéket, amely magában foglalja a megelőző szint mértékét, hozzáadva azokat
a változókat, amelyek az adott szintet jellemzik.
A fogalmak használata
Mielőtt a mérésről lenne szó, tisztázni
kell a vonatkozó fogalmak köznapi értelmét. Míg a formális, matematikai meghatározások
egy matematikai szövegösszefüggésben elfogadhatók, a releváns fogalmak a köznapi
használat óriás terhét hordozzák, többértelműek, sokszor átfedik egymást. Az
alábbi vázlat bemutatja az összefüggést a cikkben használt fogalmak között.
Tény. A való világra vonatkozó megállapítás, amelynek az igazságát ellenőrizni
kell, lehet. A pontosság fogalma nagyon fontos, ez tükrözi a bizonyosság fokát
és a ténybe vetett bizalmat. Nagyon fontos a tény ellenőrzésének lehetősége.
Az, hogy valami tény, nem jelenti azt, hogy igaz, pusztán annyit, hogy az igazsága
ellenőrizhető. Bár a tények a való világot tükrözik, sohasem teljesek, mindig
hiányosak. A tény a való világ kivonata", csak részben tükrözi a világ bonyolultságát.
Legjobb esetben olyan eszköz, amely lehetővé teszi, hogy a világot bizonyos
szempontból és bizonyos célból kezeljük.
Adat. Feljegyzett, rögzített szimbólumok. A rögzített szimbólum fogalmát
a szerző egyelőre primitív" fogalomként használja, jelentése a sajátos helyzetekben
derül ki. Az adat lehet betű, a mágneses szalag bitje, kimondott szavak, képek,
DNS és RNS, pénzügyi számadatok stb. A fogalom értelmezése szinte korlátlan.
A mindennapi életben az adat fogalmát gyakran a számadatokra redukálják, de
itt szélesebb értelemben használjuk. Sokszor az adatot azonosítják a ténnyel,
de a szerző formálisan megkülönbözteti a kettőt: az adatok rögzített jelek,
amelyek reprezentálhatják a tényeket. Az adat tehát nem tény, s ha ilyenként
kezeljük, számos tévedést okozhat. Az adatnak, így értelmezve, nem biztos, hogy
köze van a való világhoz vagy a tényekhez. (PI. a számítógépes programok, regények,
propaganda stb.)
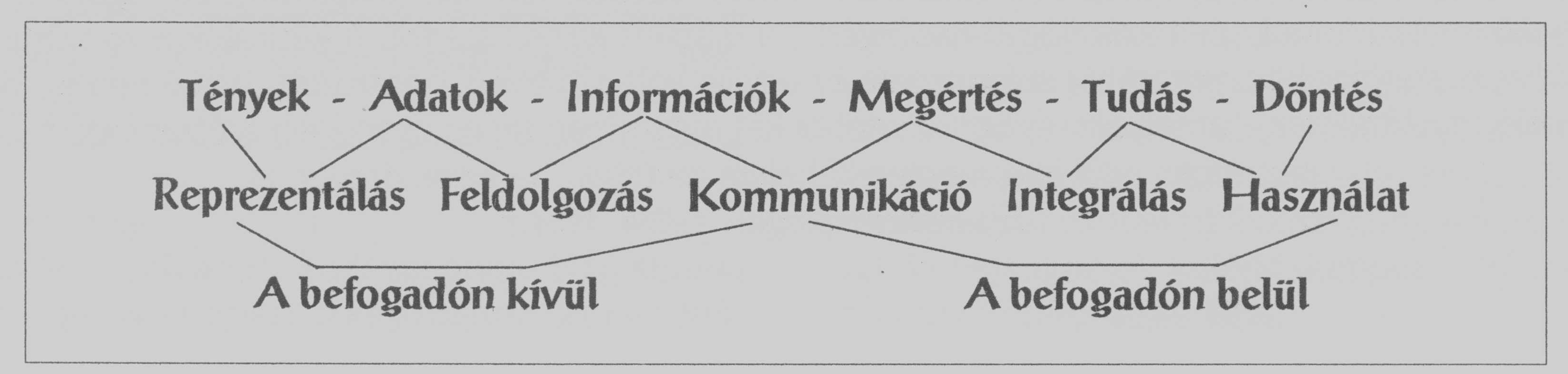
Reprezentálás (ábrázolás). Ebben
a kontextusban döntő az adatok felhasználása a tények reprezentálására, rögzítésük
céljából és hogy információt származtassunk belőlük. Így értelmezve az adatot,
két lépéssel távolodunk el a valóságtól. A tény a való világ, az adat pedig
a tény ábrázolása. A pontosság nagyon fontos. Míg a tény elvileg pontosan ábrázolja
a való világ valamely aspektusát, amikor az adatot rögzítjük, majdnem bizonyosan
veszteség lép fel az eszközök korlátai miatt.
Információ. A szerző a fogalomnak egy olyan formális meghatározását adja,
amely a Shannon féle meghatározást kívánja általánosítani.
A köznapi használatban az információ fogalma sokkal gazdagabb, elmosódottabb.
Paisley formalizálta a hétköznapi értelmezést oly módon, hogy az információt
részlegesen azonosította a gondolkodás struktúrájában bekövetkező változással.
Azt mondja, hogy ... információ minden inger, amely a befogadó kognitív
struktúráját megváltoztatja... Amit a befogadó már tud, az nem változtatja meg
a kognitív struktúrát, az nem információ. "
A szerző ebben a cikkben a kognitív struktúrát a tudással azonosítja. Az információ
hatása valóban változás lehet a tudásban, de nincs ok arra, hogy az információ
meghatározását egy ilyen változáshoz kössük. Ilyen értelemben különböző fokozatokat
azonosíthatunk: információhoz jutás, az információ birtoklása, informálttá válás,
informáltnak lenni. Ezek a fokozatok tükrözik a belsővé válás folyamatát. Az
ember kaphat információt, s mégsem válik informálttá. Az informáltság a személy
belső állapotát jellemzi.
Belkin, aki az információ fogalmának legszélesebb körű áttekintését adta,
az alábbi felsorolást közli:
|
1. az emberi
tudás része; |
Más megközelítésben az információ fogalmával a következő összefüggésekben találkozunk: tudományos és műszaki információ", üzleti információ" (bizonyos cél érdekében szervezett adatcsoport). Ezekben az esetekben többről van szó, mint egyszerű adatokról, itt a feldolgozás, szervezés, az értelmezés, az elosztás bizonyos szintjeivel van dolgunk, s ez az a többlet, amit információnak nevezhetünk. Ehhez kötődő, de mégis eltérő sort jelöl az információs rendszer" kifejezés, amelyben a figyelem központjában a feldolgozás, előállítás, elosztás mechanizmusa áll. Ennek a használatnak az általánosítása tükröződik a ;,nemzeti információpolitika", az országos információs hálózat" kifejezésekben, amelyekben a hangsúly az adatról és adatszervezésről a politikai és társadalmi vonatkozásokra tolódik. Végül itt van az információtudomány" kifejezés, amely magába foglalja a tudományos információt, a könyvtár- és információtudományt, a számítógéptudományt.
Feldolgozás. Az eddig tárgyaltak értelmében az információ lényegében az adatfeldolgozás függvénye. Az adatfeldolgozásnak legalább négy szintje van: átvitel, válogatás, elemzés és redukció. A legalsó szint az adatátvitel vagy -átadás. A vevő valamilyen szintű információhoz jut, még akkor is, ha az adaton semmiféle műveletet nem végzünk, csak továbbítjuk. A második szint az adatválogatás, szelekció. Például egy adatbázisból egy kérésnek megfelelő releváns rekordok kiválasztása. Ez a folyamat magában foglalja az adatátvitelt is, de sokkal több annál, mivel a vevő a válogatás eredményeképpen jut információhoz. Az információ mennyisége nyilván attól függ, hogy a szelekció mennyi releváns információt tud azonosítani.
A harmadik szint az adatelemzés (analízis). Erre legjobb példa az adatok struktúrálása. A vevő információt kap nemcsak az átvitel, vagy a szelekció eredményeként, hanem a struktúra által szolgáltatott összefüggésekből is. Egy információkereső rendszer esetében az adatelemzés illusztrálható a kiválogatott rekordok valamilyen feltétel szerinti elrendezésével. Egy adatbázisban példaként szolgálhatnak az adatszervezésnek olyan formái, mint a mátrix vagy táblázatrendszer, a kapcsolatok kialakítása.
A negyedik szint a redukció (tömörítés). Ezt legjobban illusztrálja az adathalmaz helyettesítése egy egyenlettel. Ilyen eljárás a lineáris regressziós analízis. Az eredmény egy olyan információ, amely részben a redukciónak, részben a nagytömegű adathalmaz néhány paraméterrel való helyettesítésének eredménye.
Kommunikáció. A kommunikáció fogalma éppen olyan sokértelmű, mint az információé. Az OED a meghatározások széles skáláját sorolja fel, az információk közlekedésétől" az eszmék cseréjéig. A különböző jelentések tükröződnek az olyan kifejezésekben, mint az interperszonális kommunikáció, tömegkommunikáció, telekommunikácó. Ezekben hol a folyamatra, hol a tartalomra, hol az eredményre van utalás.
A vevő. Eddig a hangsúly az információra, mint a felhasználón kívüli dologra helyeződött. Sokszor azonban a fogalomnak a felhasználó szempontjából fontos alkalmazásai vannak: Információszükséglet, információfelhasználó, információkeresési szokások. Ebben a cikkben ez a perspektíva nagy mértékben érvényesül, de ez bizonyos magyarázatot igényel. Az információfelhasználó megerőltetés nélkül azonosítható az információ vevőjével, főleg azzal a személlyel kapcsolatban, aki egy bizonyos szinten feldolgozott információt keres. Az információkeresési szokás így az a mechanizmus, amellyel a felhasználó kezdeményezi és meghatározza az információ feldolgozását.
Megértés. A kommunikációnak csak
akkor van értelme, az adatokat vagy az adatfeldolgozásból származó információkat
csak akkor lehet jelentéssel felruházni, ha megértjük. A megértés bonyolult
folyamat. A legalsó szinten az információ struktúrájának és tartalmának a felismerését
jelenti. A második szint a tartalom összehasonlítása a szótárakkal". A következő
szint az információnak mint entitásnak a megértése. Még magasabb szinten az
információt beépítjük a meglevő tudástárba, összehasonlítás, szembeállítás,
összevonás, szervezés, javítás vagy más változtatás révén.
A megértés belső folyamat eredménye, amelyben az adatokat
összevetjük valamely listával és értelmezzük a jelentésük alapján. Például az
A" adatként továbbítva egyszerű nagy a" betű, de a belső kódkönyvvel összevetve
Alarm". Előfordulhat, hogy a közvetített adat elvész, mivel nem értelmezhető,
a belső listákban nincs megfelelője. Ebben az esetben a kommunikációnak addig
kellene folytatódnia az adó és vevő között, amíg létre nem jön a megértés. A
megértés mindig magába foglalhatja a félreértés lehetőségét.
Tudás (ismeret).
Ennek a fogalomnak a használata is nagyon kiterjedt, diffúz. Lényege, hogy
míg az információ külsődleges és kapható, felvehető, a tudás belső, nem lehet
kapni, hanem belsőleg kell létrehoznunk.
Nitecki a tudás fogalmának, és főleg az információ és a tudás közötti
összefüggésnek a formalizására tett kísérteteket tárgyalja. Három felfogást
különböztet meg: 1. a két fogalom azonos vagy közel azonos (az információ a
tények tudása, a tudás a reprezentálás által feldolgozott információ), 2. a
két fogalom kölcsönösen kizárólagos (az információ az adat, a tudás kikövetkeztetett
lényeg, az információ kívülálló, a tudást az ember hozza létre), 3. a két fogalom
azonos, amikor a tartalomról van szó, de különbözik, amikor az információ folyamatorientált,
és a tudás tartalomorientált. Ebben a cikkben a szerző a második nézetet teszi
magáévá. A tudás a közölt információ megértéséből és a korábbi információkkal
való integrálásból származik. A tudás az információ belsővé tételének eredménye,
de több annál, aktív folyamat a kognitív struktúra restruktúrálása - ahogy azt
Paisley értelmezi. Ami szerinte az információ funkcionális" jellegzetessége,
az itt tudásként szerepel. Fontos megjegyezni, hogy a kognitív struktúra két
elemét kell megkülönböztetni: az internalizált információkészletet a maga struktúrájával
és az intelligenciát" mint a belső feldolgozás eszközét. Bár mindkettő fontos,
a cikk a tudás fogalmát a kognitív struktúrába épített alapvető információtárra
szűkíti.
Nitecki az integrációnak egymás után következő három fokozatát különbözteti
meg : 1.) a kezdeti tudás, mint egy adott ténynek a passzív reflexiója; 2.)
más, hasonló passzív reflexiókkal való interakció; 3.) ezek kombinálása szélesebb,
átfogóbb entitásokká.
Fontos megjegyezni, hogy a tudás az entitások széles körében van jelen. Az egyénben
belső, kognitív struktúrája részeként található; az egyéni intelligencia így
az az eszköz, amellyel az egyén a tudást felhasználja (pl. döntésre). A tudás
létezhet könyvtárban, mint a feljegyzések, rekordok gyűjteménye; A könyvtár
intelligenciája a szakembereiben és nemszakembereiben felhalmozott tapasztalat,
intelligencia. A tudás testet ölthet a szakértő rendszerekben is (tudásalap).
Létezhet a társadalom emlékezetében, a társadalmi intelligencia így az az eszköz,
amellyel a társadalom az emlékezetét használja.
Az információmennyiség mértékei
Az információ mérése bonyolult és még megoldatlan
probléma. Mégis a szerző az információmértékeknek olyan sorozatát javasolja,
amelyben mindegyik a megelőzőnek az általánosítása (az információnak előzőleg
adott definíciója alapján, amely azonosítja azt, az adatoknak feldolgozásukból
származó tulajdonságával). A feldolgozásnak legalább négy szintjét különbözteti
meg.
Az első szintnek - az adatátvitelnek - van jól definiált mértéke, a következő
háromra a szerző olyan mértékeket javasol, amelyek az információ növekvő komplexitását
tükrözik.
A kommunikáció (adatátvitel) shannoni
mértéke
Az egyetlen hivatalosan", formálisan elismert mérték a Shannon által
kidolgozott és az információelméletben alkalmazott mérték. Az információ mennyiségét
méri, de nem az értékét. A cikk a továbbiakban részletesen ismerteti a shannoni
elméletet.
A szerző, mielőtt rátérne a mérték általánosításának heurisztikai .megalapozására,
szükségesnek tartja a mérték szemantikai bemutatását. A vevőnek szüksége van
arra, hogy meghatározza a jel értelmét, s ehhez össze kell vetnie valamely belső
táblázattal. A jel által szolgáltatott információ mértéke egyenlő az összevetés
során végrehajtott bináris döntések számával (feltéve, hogy a táblázat megfelel
a jel kódolásának). Az alapul szolgáló paraméter a táblázat mérete (azaz a szócikkek
száma), amely a kommunikációban felhasznált szemantikus szótár terjedelmével
egyenlő.
Súlyozott entrópia (adatszelektálás)
A shannoni mérték nagyon jól beválik, amikor az adatátvitel hatékonyságát
vizsgáljuk. De alig, vagy egyáltalán nem használható, amikor a bármilyen formában
mért jel értéke fontos. A shannoni mérték általánosítása, a súlyozott entrópia",
úgy tűnik, egyaránt kifejezi a hatékony átvitel statisztikai igényeit és a jel
fontosságát a vevő vagy felhasználó szempontjából. Ez a mérték minden xi
jelhez az a priori valószínűség mellett hozzárendel egy ri; = r(xi)
értéket, ami a fontosságát méri. A fontosságnak egy ilyen mértéke illusztrálható
a relevanciával" olyan értelemben, ahogy azt az információkereső rendszerek
értékelésénél használják. Az eredményül kapott súlyozott entrópia mérték, amit
jelentőség-nek nevezünk (significance) egy adott jelre, illetve egy egész
jelkészletre:
xi jelre:
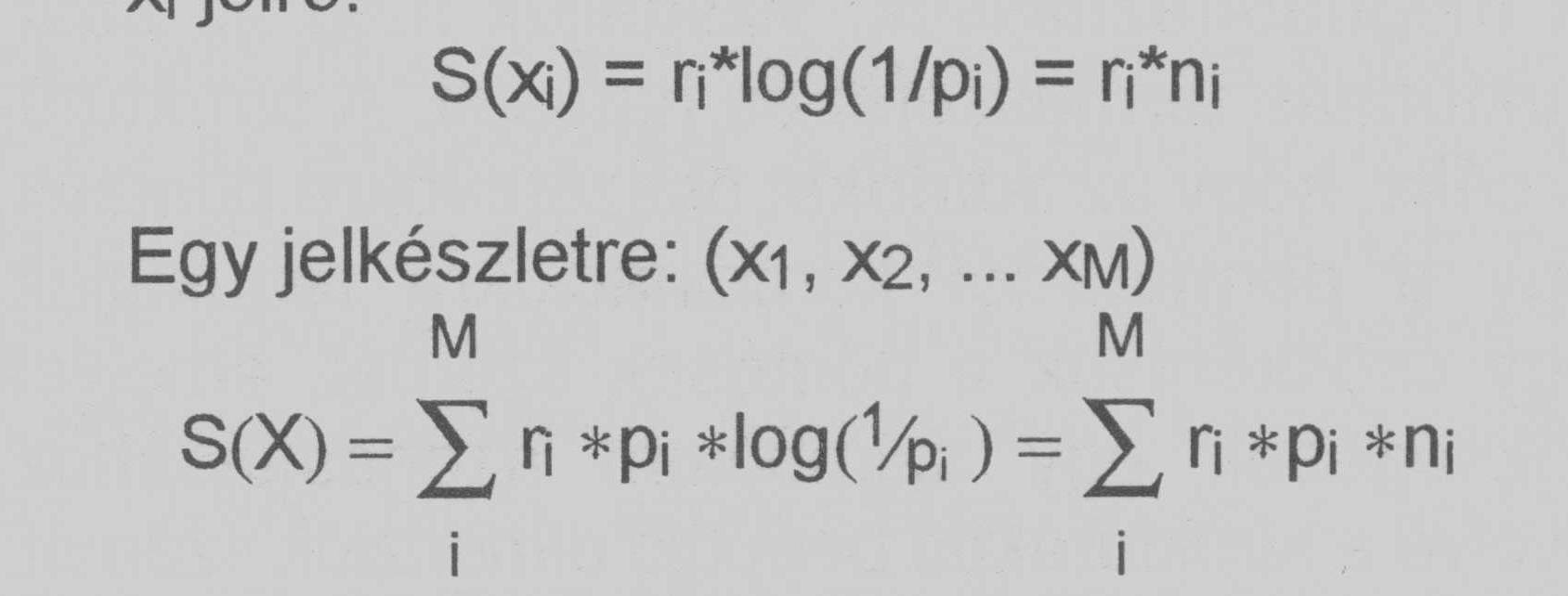
Ha minden jel egyenlően fontos, ami szükséges
feltétel egy távközlési rendszer tervezésénél, a súlyozott entrópia mérték a
shannoni mértékre redukálódik. Ha mindegyik jel egyforma valószínűségű, a mérték
a relevancia mértékére redukálódik, amelyet az információtárolás és -keresés
területén használnak.
Hogy ennek az információmértéknek a heurisztikus igazolását megkapjuk, vegyünk
egy fájlt, amelyből információt keresünk. Egy tétel N bit információt tartalmaz
és legyen egy Y kérés, amelyet összevetünk minden tétellel, hogy azonosítsuk
azokat, amelyek megfelelnek egy n készletnek az N bitekből. Mekkora az információmennyiség,
amelyet a fájl szolgáltat egy ilyen kérésre?
Határozzuk meg a jel "jelentését" mint két egymással kapcsolódó mennyiség -
p(xi) az a priori valószínűség és r(xi) a relevancia -
függvényét: S(xi) = S(p(xi),r(xi))
A heurisztika leírásának egyszerűsítése érdekében tételezzük fel, hogy minden
tétel N bitet tartalmaz, hogy mindegyik egyenlő valószínűségű, és hogy r(xi)
az N bitnek az a hányada, amely xi és az y kérdés fedése által jön
létre. Akkor:
S(xi) = S(1/2N,(xi AND y)/N)
Válasszunk ki egy másik tételt a fájlból. Ésszerű feltételezni, hogy a mindkettőjükben található információ mértéke úgy kezelhető, mint a kettő összege, azaz
S(xi,xj ) = S(xi)+S(xj )
Ennek a függvénynek a megoldása a javasolt mérték:
S(xi) = r(xi)*log(1/p(xi))
Szemantikus kontra szintetikus információ (adatelemzés)
Hogy az adatfeldolgozás harmadik szintjéhez
- az analízishez és adatszervezéshez - a mértéket meghatározhassuk, vizsgáljuk
meg az adatstrukturálás természetét és hatásait. A strukturálás célja, hogy
az adatokat összetevőkre bontsuk, hogy a permutációt kombinációkra redukáljuk,
hogy csökkentsük a döntések számát, amelyek szükségesek egy szimbólum azonosításához,
növelve a struktúrákba beépülő dimenziók számát.
Ennek illusztrálására vegyünk egy szimbólumkészletet. Ha minden szimbóluma egymástól
független (nincs struktúrája), a vevőnek a kapott jelet az egész készlet minden
jelével össze kell vetnie, hogy megtudja, mit jelent. Ha van struktúra, pl.
a szimbólumok mezőbe vannak rendezve, jelentősen csökkentjük egy jel azonosításához
szükséges döntések számát.
Ugyanezt a célt szolgálja az adatok mátrixba rendezése. Ebben az esetben csak
(N+M) tárggyal van dolgunk (NxM) helyett (N és M a mátrix méretei). Itt két
probléma merülhet fel: nem mindegyik szimbólumot jellemzi egyértelműen a struktúra
(pl. egynél több elem lehet ugyanabban a kategóriában), nem mindegyik kategória
van reprezentálva. Ezek azonban nem módosítják a lényeget.
Mérhető-e ez a hatás?
Legyen a forrásjel hossza N bit (úgy, hogy van 2 jelünk). Osszuk F mezőre, amelynek
hossza (n1, n2 ... nF) bit, átlagosan N/F bit.
Ahelyett, hogy keresnünk kellene 2N elem között, mindössze (2ni)-k
összegében kell keresnünk. Az eredeti N bit információt ennek az összegnek a
logaritmusa hordozza. Ezt nevezzük szemantikai információnak, mivel ez az a
része a teljes szimbólumnak, amely a táblázatban való keresést foglalja magában
(jelentés), a maradék a szintetikus információ", amit a struktúra hordoz. Ha
F nő, a szemantikus információ gyorsan csökken és a szintetikus információ nő.
Hogy a szemantikus és szintetikus információ közötti megoszlás mértékét meghatározzuk,
vegyünk egy F mezőből álló rekordot. Mindegyik mező lehetséges értékéhez rendeljünk
hozzá egy a priori valószínűséget. Így a j mezőhöz és i értékhez tartozik egy
(pji) valószínűség. Valamely sajátos független kombináció valószínűsége
pji szorzatával és a szimbólum által hordozott információmennyiség
ennek a szorzatnak a logaritmusával egyenlő. Ez a teljes információmennyiség
feloszlik szintetikus és szemantikus információra:

Ez a mérték azonosítja az analízis és szervezés
folyamatát az eredeti szimbólum alkotó mezőire való felbontásával és a kapott
struktúrát a szintetikus eredménnyel. Az eljárás által létrehozott információ
ilyenformán a szintetikus információ.
Ha csak egy mező van (F=1), a szintetikus információ egyenlő zéróval és a szemantikus
információ egyenlő az eredeti entrópiával. Ez azt jelenti, hogy a javasolt mérték
következetes általánosítása az entrópia mértékének.
A szerző utal arra, hogy a javasolt mérték paraméterei szerepet játszanak az
adatelemzéshez és adatredukcióban.
Adatredukálás
Az adatfeldolgozás utolsó fázisa az adatredukálás, pl. faktoranalízis,
görbeillesztés, az adatok csoportosítása, nagy számú adat néhány paraméterre
való redukálása útján.
Vegyünk például egy F teszteredmény-sorozatot (amelyet N bit képvisel) M személyre
vonatkozólag (klasszikus példa a faktoranalízisre). Ez úgy tekinthető mint egy
(M*N) mátrix. A sajátvektor-analízis, a faktoranalízis stb. azok az eszközök,
amelyekkel egy másik alapot lehet meghatározni (dimenzionális transzformáció).
A vektorként tekintett adatokat így vetületükkel lehet ábrázolni az új alapon.
Gyakorlatilag minden valóságos esetben az új alapvektoroknak csak kis része
járul hozzá szignifikáns módon az eredeti adatok reprezentálásához. Az eredeti
adathalmazt annyira le lehet redukálni, hogy 100 érték 5 értékkel helyettesíthető.
Hogyan mérhetjük az ilyen adatredukció révén átvitt információt? Mint előbb,
az információ teljes mennyiségét az eredeti forrásadatok reprezentálják. (F
fájl minden M rekordra). A szemantikai feladat a vevő számára arra redukálódik,
hogy átnézzen egy G rekordból álló táblázatot. Az információ megoszlása a feldolgozás,
a szintaktikai struktúra és a szemantikai keresés között (mindegyikük hozzájárulása
a teljes információmennyiséghez) a következő:
Releváns változók: gk, fj, xji, p(xji),
r(xji); M,F,G. Az egyes összetevőkhöz rendelt mértékek:
reduktív:
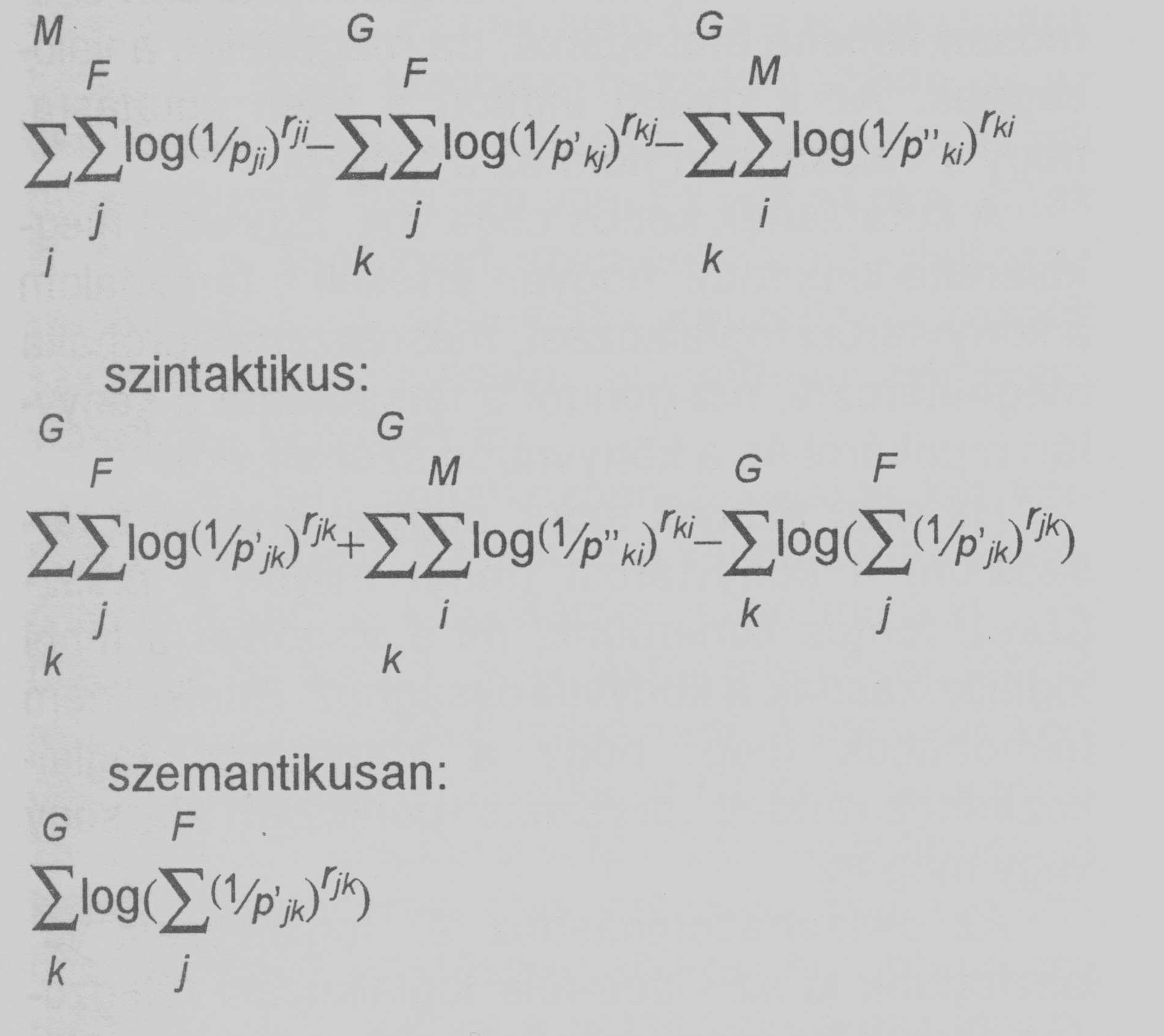
Következtetések
Befejezésként vegyük szemügyre az információ
és a kommunikáció közötti kapcsolatot a fentebb meghatározott mértékek kontextusában.
Intelligens kommunikácó" az információfeldolgozás három komplex szintjén -
a szelekció, az analízis és a redukció szintjén. Mindegyik esetben az információ
forrása hozzáad valamilyen feldolgozási formát az egyszerű adatátvitelhez, s
így a vevő több információhoz jut, mint amennyi az átvitt bitek puszta mennyisége.
Az interaktív kommunikáció" sokkal több, mint az adó és vevő egyszerű váltakozó
szerepcseréje, sokkal mélyebb a hatása. Ha megnézzük a feldolgozás különböző
szintjeit, mindegyiket sajátos paraméterek jellemzik: p(xi), r(xi),
F és G - az a priori valószínűségek, relevanciák, a fájlok és az adattér alternatív
alapjainak meghatározásai. Az igazi interakció akkor jön létre, amikor a kommunikácós
folyamat eredményeként ezekre a paraméterekre váltanak át.
Interaktív kommunikációra akkor van szükség, amikor az adó és a vevő nem egyformán
fogja fel, érzékeli a jellemző paramétereket. Különösen a kommunikációs csatornában
fellépő zaj okozhat hibákat az adatátvitelben és befolyásolhatja az adatkódolást.
A klasszikus kommunikációelméletben alaptétel, hogy a zajszint exponenciális
növekedése a jelek hosszának lineáris növelésével kezelhető. Az interaktív kommunikáció
az átviteli hibák azonosítása során a kódolás eszközeinek megváltoztatását eredményezheti.
Az adatszelektálásban a csatornazaj megfelelője az átvivendő adat bizonytalansága".
Ennek forrása egyrészt az indexek hozzárendelésében megnyilvánuló bizonytalanság
- még a legtapasztaltabb indexelőknél is előfordul -, s ezzel párhuzamosan a
kérdések megfogalmazásában jelentkező bizonytalanság, másrészt az adó és a vevő
eltérő véleménye az r(xi) értékét illetően, amint azt a relevancia
megítélése illusztrálja. Azok a módszerek, amelyeket a csatornazaj kezelésére
alkalmaznak, itt nem felelnek meg, mivel a hiba a forrásadattal és a feldolgozással
kapcsolatos, nem az átvitellel. Hogyan kezeli a rendszer a bizonytalanságot?
A kiválasztott és átvitt üzenetek számának növelésével növelik a találatok (értékes
üzenetek) számát, igaz a pontosság" csökkenésének árán. A válogatás minőségének
javítása megkívánja az interaktív kommunikációt, hogy növelni lehessen az egyezést
a forrás és a vevő szótára .között és az érték mérésében.
Az adatstruktúrálással kapcsolatban a jellemző probléma, hogy a szintaktikus
struktúrák nem egyeznek. Ez esetben is az analízis minőségének javítása megköveteli
az interaktív kommunikációt, hogy a struktúrát a forrás és a vevő ugyanúgy észlelje.
Az adatredukciónál fellépő problémák az alkalmazott eljárással függnek össze.
Ha egy többdimenziós adatteret redukált számú dimenzióval próbálunk ábrázolni,
a forrásadatok pontosságában veszteség lép fel. A pontosság és hatékonyság közötti
egyensúlyt az interaktív kommunikáció révén lehet biztosítani.
![]()
| Országos Széchényi Könyvtár Észrevételek (2000/04/12) |