37. évfolyam, 1991. 2. szám
| 37. évfolyam, 1991. 2. szám |
Archívum |
Szakértő rendszerek a könyvtárakban
Az utóbbi néhány évben fokozott érdeklődés figyelhető meg a szakértő rendszerek iránt. A szakértő rendszerek fogalmát nehéz körülírni, mert a meghatározások csak körülbelüliek, bizonytalanok, szakemberenként más és más elemeket tartalmaznak. Jelentős a terminológiai bizonytalanság, melyet jól érzékeltet az a tény, hogy idehaza egyaránt használják a szakértő és a szakértői rendszer kifejezést is.
A továbbiakban az angol Könyvtárosegyesület Információtechnológiai, valamint a Könyvtári Információkutatási csoportja 1985-ös konferenciájának anyagából vett példákkal illusztrálom a szakértő rendszerek működési mechanizmusát.
Ezeknek a rendszereknek vannak jól körülírható alaptulajdonságaik. Jellemzőjük, hogy tényekből, összefüggésekből és heuriszikából (feladatmegoldási algoritmusokból) felépülő szervezett tudást foglalnak magukba, amely tudás egy meghatározott szakterületre terjed ki. A szakértő rendszereket többé-kevésbé összetett problémák megoldásában konzultánsként/segítségnyújtóként használják, mivel legalább úgy tudnak (esetenként jobban) problémákat megoldani, mint a humán szakértők. Problémamegoldáshoz a szakértők által jónak ítélt heurisztikát használják és bizonyos fokig azok döntéshozási mechanizmusait utánozzák. A rendszerekben tárolt tudás elkülönül a felhasználására szolgáló mechanizmusoktól. Igen sokan fontosnak tartják azt is, hogy a szakértői rendszerek képesek legyenek következtetéseiket megindokolni.
Nem univerzális problémamegoldó rendszerekről van viszont szó. A szakértő rendszerek működése a dolog természeténél fogva csak egy-egy szűk szakterületre korlátozódik. Nem képesek a jóslásra sem. A szakértő rendszerek elsődleges összetevője a tudásbázis, azaz egy adott területről származó tények, összefüggések és heurisztika összessége. A tudásbázis minősége a rendszer hatékony működése szempontjából meghatározó.
Egy adott terület szakértője egyedül nem képes arra, hogy a tudásbázist létrehozza, ezért együtt kell működnie az ún. "tudásmérnökkel" (knowledge engineer), aki a szakértő rendszer számára megteremti a "fogyasztható", formális tudásreprezentációt. A tudásreprezentáció egyik lehetséges útját a szabályalapú rendszerek jelentik, melyek a HA...AKKOR relációra épülnek. A szabályok lehetnek egyszerűek, azaz egy feltétel egyetlen következtetést vonhat maga után: HA hideg van, AKKOR vegyél fel meleg ruhát. Tartalmazhatnak többszörös feltételt és következtetéseket: HA reggel elalszom ÉS be kell érnem az értekezletre, AKKOR felhívom a munkahelyemet, VAGY taxival megyek. Több feltétel is vezethet egyetlen következtetéshez: HA elvesztem a pénztárcámat, VAGY a csekkönyvemet, AKKOR informálom erről a bankomat. Egyetlen feltétel több következtetést is indukálhat: HA nem jön a vonat, AKKOR busszal megyek, VAGY fogok egy taxit.
Előnye ezeknek a szabályoknak, hogy könnyen megalkothatók, és hogy az egyik feltételből eredő következtetés egyúttal egy másik szabály feltételrésze is lehet és ilyen módon a szabályok egész hálózata építhető fel.
A tudásreprezentáció másik fő formája a szemantikai hálók kialakítása. Ezekben csomópontokat és köztük fennálló relációkat találunk.
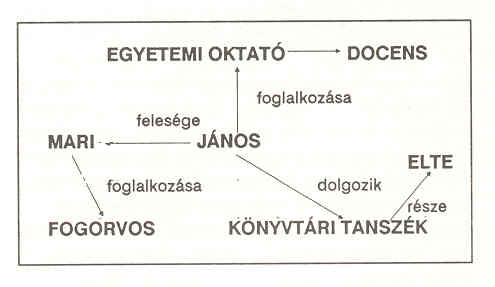
A szemantikai háló lényege a következő példával illusztrálható:
A szemantikai hálók képesek komplex fogalmakat és hierarchiákat gazdaságosan reprezentálni, mivel a kapcsolatok "örökletesek". Ez azt jelenti, hogy JÁNOS-hoz nem kell az előző példában a DOCENS fogalmát kapcsolnunk, mert az az EGYETEMI OKTATÓ fogalmával "öröklődött".
Van a tudásreprezentációnak egy harmadik módja is, a tudáskeretek ( frames ) alkalmazása. Ezek arra az elképzelésre épülnek, hogy a tárgyak a cselekvések és események proto-, illetve sztereotipikus formában megfoghatók. A keretrendszer az ezekre vonatkozó információt felismerhető egységekbe gyűjti. Egy-egy ilyen egység között kapcsolatok építhetők ki az összefüggések alapján. A keretekben üres helyek ( slots ) vannak, amelyek ismeretekkel töltődnek fel. Egy leegyszerűsített példával illusztrálva ezt: a rendszerbe belépő input, a címlapon szereplő " proceedings " szó arra készteti a rendszert, hogy kezdje meg a "konferencia" keret üres helyeinek kitöltését. A " symposia " vagy a " meeting " szó megjelenése azt váltja ki, hogy a rendszer adatokat kérjen az adott konferenciatípus keret üres helyeinek kitöltéséhez.
Ahhoz, hogy a rendszer hatékonyan működjön, szükség van olyan eszközökre, amelyek eldöntik, mely szabályokat kell aktiválni egy adott helyzetben. Ennek legegyszerűbb módja, ha ez az egység, amelyet több elnevezéssel illetnek - nevezzük inferencia (következtetési) rendszernek - végignézi az összes szabályt, mindaddig, amíg nem talál olyat, amelynek előzményei nem azonosak a probléma kiváltotta inputtal. Ekkor a rendszer alkalmazza a szabályt és a keresés tovább folyik mindaddig, míg a döntés meg nem születik, vagy nem talál alkalmazható szabályt. A rendszer kapcsolatot tarthat a felhasználóval, hogy az adódó konfliktusokat feloldja, vagy a felhasználó válasszon az alkalmazandó szabályok közül, ha a kérdés nem egyértelmű. Ez az adatvezérelt stratégia.
Alternatív stratégia az, amikor a rendszer hipotézist választ és megvizsgálja, levezethető-e az az input kérdésből. Ebben az esetben azokat a módszereket keresi a rendszer, amelyekkel elérhető az adott cél, e szabályok feltételeit pedig összehasonlítja a probléma definíciójával. A rendszer ebben az esetben is kapcsolatot tart a felhasználóval, hogy a konfliktus helyzetet feloldja. Ez a megoldás a célvezérelt stratégia.
Kifinomultabb rendszerek mindkét stratégiát alkalmazzák, de a célvezérelt stratégiák általában hatékonyabbak mint az adatvezéreltek, mivel kis számú input esetén is több lehetséges megoldáshoz vezetnek. A rendszerben szükség van egy globális adatbázisra is, amely tartalmazza az adott témához tartozó adatokat és magába foglalja a rendszerben eddig feldolgozott problémafelvetéseket. Végül, de nem utolsósorban szükséges még egy, a felhasználóval való kommunikációt biztosító interfész. 1
A szakértő rendszerek fejlesztése elsősorban a szakértőknek egy-egy területen meglevő tudását próbálta átadni a rendszereknek és kevesebbet törődött azzal az ismerettel, amely a tudás forráshelyeire vonatkozik, pedig ez utóbbi a könyvtári tájékoztató munka központi kérdése.
A tájékoztató munka tág értelmezése szerint a tájékoztatás feladata annak biztosítása, hogy az információ az információforrásoktól az információt igénylőkhöz szabadon áramolhasson, s ebbe a körbe más információs szakemberek, így pl. az online közvetítők tevékenysége is beleértendő. A szakértő rendszerek nem teszik fölöslegessé az ő munkájukat, ugyanis lehetővé teszik, hogy a referensz könyvtárosok mentesüljenek a rutinmunkától, és az összetettebb, nagyobb kihívást jelentő problémákra irányíthassák figyelmüket.
Az információs szolgáltatások kihasználtsága gyakran alacsony. Ez egyrészt azért van így, mert a felhasználók nem tudnak (még) létükről, vagy vonakodnak őket igénybe venni, másrészt viszont a tájékoztatási szakemberek száma túl kevés ahhoz, hogy megbirkózzanak az igényekkel. Ha a felhasználónak a szakértő rendszerekkel segítünk a közvetlenebb hozzáférésben, a könyvtáros szerepe éppenséggel felértékelődik majd, hiszen ő lesz az, akihez akkor fordulnak, amikor a kérés összetettebb annál, mint amit a rendszer kezelni tud, vagy hatókörén, témáján kívül esik.
Az egyik program, az "Expert System for Referral" elnevezésű, a British Library támogatásával jött létre a University of London központi információs szolgálatánál. A projekt fő célkitűzése az volt, hogy olyan alkalmazást dolgozzanak ki, amelynek segítségével bemutathatják a könyvtárosoknak a szakértő rendszerek jellemzőit és lehetőségeit. A program prototípus rendszere a PLEXUS volt, amely egy jól körülhatárolt szakterület, a kertészet vonatkozásában segítette a felhasználót a problémájának megfelelő információforrás azonosításában.
A rendszer kialakításához részletesen elemezték a tájékoztatás folyamatát és öt lépésben foglalták össze a rendszerfunkciókat:
A négy már működő rendszerfunkció mellett elkészült az alkalmazott kifejezések szótára, a referencia-források adatbázisa és egy hierarchikus osztályozás is.
A rendszerrel kapcsolatba lépő felhasználó először is rövid leírás kapta PLEXUS szolgáltatásairól. Ezután lép működésbe a GETUM modul, melynek segítségével kialakítják a felhasználói modellt. A felhasználói modell felépítésére - a felhasználóval folytatott párbeszéd alapján - hat jellemző szolgál: a felhasználó ismeretei a rendszerről; az információkérés tárgya és a felhasználó foglalkozása közötti összefüggés; a felhasználó gyakorlati tapasztalata az adott területen; ismeretei a terület információforrásairól; milyen segítséget kért eddig stb. A modell elkészülte után, ha a felhasználó elégedett annak pontosságával, megkezdődik a felhasználó problémájának modellezése. A rendszer nem kérdezi, milyen forrásokhoz szeretne fordulni a felhasználó, és azt sem várja el, hogy a felhasználó formális módon határozza meg a kérdését, elég a körülírás is.
A GETSTAT modulhoz kapcsolódó tudásbázis lehetővé teszi, hogy a rendszer eldönthesse, hatókörébe esik-e az adott témájú információkeresés, és ha igen, elegendő-e az egy hatékony keresési stratégia kialakításához.
Ha a PLEXUS nem "értette" meg a felhasználó kérését, böngészési lehetőséget nyújt, amelynek segítségével a kereső áttekintheti a rendszer hatókörébe eső témákat. Ez különösen azoknak a felhasználóknak jó, akik nem ismerik a szokványos adatbeviteli formákat. Másik előnye, hogy egyúttal részletes képet is kap a rendszer képességeiről. Ha a felhasználó nem tud megfelelő fogalmat találni, a rendszer tudatja vele, hogy nem képes kérdésére válaszolni, és kikapcsol.
Ha a PLEXUS a felhasználói kérdésből csak egyes fogalmakat értett meg, a továbbiakban megpróbálja az ismeretlen fogalmakat is azonosítani. "Tudja", milyen fogalmakat kell várnia a hatókörébe tartozó problémákkal kapcsolatban, ezért kérdéseket tesz fel annak kiderítésére, melyik fogalomkörbe tartozik az ismeretlen fogalom. (Pl. Növény? Növény része?) A "megértett" fogalmat felveszi szótárába. Ezután következik a probléma modellezése a tudáskeretekre alapozva. Ha a modell nem teljes, a rendszer kiegészítő információkat kér a felhasználótól.
Ha már kielégítő a modell, keresési stratégiává alakítható. Az első kérdés alapján kapott találatok számát figyelembe véve a rendszer szűkítheti, vagy bővítheti a keresőkérdést.
Az amerikai program, az Expert Assistan projekt ( University of Massachusets ) azzal a céllal készült, hogy egy információkereső rendszerbe beépítsen egy olyan "szakértő konzultánst", amely többek között ismeri a különböző felhasználói típusokat, az információkérés megformálásának módszereit, a különböző keresési stratégiákat, ilyen módon segítve a felhasználókat. A "szakértő konzultáns" feladata, hogy felhasználói modelleket alkosson és őrizzen meg, ezekkel reprezentálva az egyes egyedi felhasználókat; az információkérés során felépítse az információs igény modelljét, majd később a felhasználó visszacsatolása alapján módosítsa azt; a kérés és a felhasználói modell alapján keresési stratégiákat alakítson ki; jelenítse meg az információt a felhasználó számára és kapjon tőle visszajelzést; adjon magyarázatot a rendszer működésére. Moduljai között van egy böngészési lehetőséget adó, és egy a rendszer képességeit, hatókörét bemutató modul. A tezaurusz-modul képes arra, hogy a felhasználó által az információkérésben megfogalmazott általános fogalmak helyett specifikusabbakat találjon. Az információkérést modellező modul a felhasználónak egyes fogalmakra, dokumentumokra, szerzőkre stb. vonatkozó véleményére alapozza döntését. Súlyozni is képes három kategória, a fogalom gyakorisága a kérésben, a felhasználó értékítélete (érdekesnek, fontosnak találja) és egy valószínűségi visszakeresési modell alapján.
A rendszer elkészíti a felhasználó modelljét és a keresőkérdést. A természetes nyelvi modul a felhasználó természetes nyelvi kérdését a rendszer belső nyelvére fordítja.
Egy másik fejlesztés alatt álló intelligens információ-visszakeresési interfész azokat a funkciókat kívánja ellátni, amelyeket a humán közvetítő tölt be, amikor a felhasználóval konzultál az elvégzendő keresésről, majd végre is hajtja azt. Ehhez szükséges: a probléma megállapítása, a felhasználói modell és a keresési stratégia megalkotása a megfelelő dialógus forma (menü, természetes nyelv) megteremtése, a felhasználótól jövő input átalakítása a rendszer belső nyelvére és az output átalakítása a felhasználó számára fogadható formára. A rendszerben a (valódi) felhasználó és közvetítő közötti beszélgetések hangszalagjait használják fel kiindulásként. Ezek lejegyzett, írott formáját részletes nyelvi elemzésnek vetették alá, amelynek alapján megkapták a fejlesztendő funkciók alapvető jellemzőit: a) azokat, amelyeket részletesebben kell specifikálni; b) a szükséges tudásbázist és az elérendő dialógus-struktúrákat. 2
Az osztályozás területén még nem számolhatunk be működő szakértő rendszerről. Kutatásokat azonban már végeztek a könyvtártudományi monográfiák osztályozásával kapcsolatban.
Az osztályozás - explicit vagy implicit módon - szabályok alkalmazása, így szabályalapú rendszerekkel elvileg jól megoldható. Az osztályozásban mindig fennáll a következetlenség veszélye, vagyis az, hogy kellő koordináció hiányában a rendszer nem lesz egységes. Inkonzisztencia forrása lehet például egy-egy könyv új kiadása is. Ha újrafeldolgozzák a könyvet könnyen lehet, hogy az új osztályozáskor más jelzetet kapnak.* Az osztályozásban a szakértő rendszerek célja természetesen nem az, hogy a könyvtárosok "gombnyomogató" operátorokká degradálódjanak, hanem az, hogy mentesíteni lehessen őket az osztályozás kezdeti szakaszában jelentkező jelzetkereső lapozgatás rutinmunkájától, vagy legalábbis csökkenteni lehessen azt. A kutatási programban a Dewey-féle Tizedes Osztályozást használták. Egyaránt foglalkoztak "kemény" és "lágy" terminológiájú területekkel. Az előbbiek a természettudományok és a műszaki területek, az utóbbiak a társadalomtudományok. A "kemény" terminológia azt jelenti, hogy ezeken a területeken a fogalmak strukturált rendszerével állunk szemben és a terminusok általánosan elfogadottak, jelentéseik többé-kevésbé standardak.
A tervezésben abból indultak ki a kutatók, hogy az automatizáláshoz szükséges a manuális folyamat megértése is. Olyan prototípus-rendszer kifejlesztésére törekedtek, amely megfelelő inputra válaszként osztályozási jelzeteket ad ki. Ennek a prototípusnak a sikere teheti majd lehetővé egy teljes rendszer alakítását.
A Dewey-osztályozás hierarchikus voltából következően a szemantikai hálók lesznek jól használhatók.
A rendszernek a PLEXUS GETSTAT modulnál már említett problémák mellett azzal is meg kell küzdenie, hogy egy-egy fogalom tudományterületenként más és más értelmezést kaphat. Így pl. a "világítás" tartozhat a villamosmérnöki tudományhoz, az építészethez, a fotográfiához stb. Ezt a problémát kétféleképpen lehet megoldani. Az egyik lehetőség az, hogy a terminust ideiglenesen tárolja a rendszer egy olyan listán, amelyen szerepel az összes olyan csomópont, amelyekhez az tartozhat. További fogalmak inputja egyre inkább szűkítené a lehetséges területeket tartalmazó csomópontok számát, idővel elérve az egyet.
A másik módszer a térképek utazás közbeni használatához hasonlítható. Ahogy vezetés közben először az autóatlaszban nézzük meg, merre tartsunk, és csak egy-egy várost elérve vesszük elő annak részletes térképét. Az osztályozási szakértő rendszer esetében ez jelentené, hogy a humán osztályozó döntené el, melyik fő osztályba tartozik az adott dokumentum. A további input fogalmakat a rendszer már automatikusan ebbe az osztályba tartozónak tekintené. Azt mondhatjuk, hogy egy gyakorlott könyvtáros éppen így dolgozik osztályozáskor. Ez a módszer különösen hasznos lehet azokban az esetekben, amikor a szavak sorrendje jelentést hordoz: pl. " the history of bibliography " (a bibliográfia története) és " the bibliography of history " (történettudományi bibliográfia). 3
Mivel a katalogizálás is szabályok által vezérelt folyamat, a vele kapcsolatos döntéshozási mechanizmusok egy része szintén automatizálható. A kérdés az, mennyire adnak választ kérdéseinkre az adatok. A többes szerzőség esetében elég a számítógépnek háromig számolnia. Ha ugyanis kettő vagy több személy, illetve testület a szerző és egyik sincs kiemelve, a szabályok szerint az első szerző neve alatt kell felvenni a dokumentumot. A különböző néven (álnéven) szereplő szerzők esetében authority fájlokhoz nyúlnak a humán katalogizálók, amit a számítógép is elvégezhet. Sok esetben a katalogizálási szabályok alkalmazásához az azokból kikövetkeztetett heurisztikákat alkalmazzák a könyvtárosok. Ezek megfelelőit a szakértő rendszerekbe is be lehet építeni. A szabályokból levont tudás még nem elégséges a katalogizáláshoz. Sok esetben csak emberi döntés segíthet a bibliográfiai feltételek megállapításában. Ennek legegyszerűbb módja menürendszer felépítése.
Vegyünk példának egy interjúkötetet. A dokumentumtípusokat tartalmazó menüből a könyvtáros a "könyv" opciót választja, amivel eljut a szerzőséget taglaló menübe, ahol a vegyes szerzőségre szavaz. Ezekben és a további menükben minden esetben magyarázatot kaphat a felosztás miértjére. Az "interjú" opció választása után kiválaszthatja, hogy a kötet főként a riporter vagy a riportalany szavait tartalmazza-e. Az előbbi választása esetében a riportalanyok számát kell kiválasztania. Ha ez pl. négynél több, a katalógusba csak az első riportalany neve kerül be. Minden adatot csak egyszer kell bevinnie a könyvtárosnak a rendszerbe és nem kell külön megjelölnie az adatok közötti kapcsolatokat.
A katalogizálási rendszerek továbbfejlesztésének egyik lehetséges módja az optikai karakterfelismerő eszközök felhasználása az inputra.
Ha ezen kívül a rendszerek képesek lennének megkülönböztetni a címlapokon található különböző adattípusokat, a könyvtárosokkal folytatott dialógust jelentősen lehetne csökkenteni. Katalóguskártyákat intelligensen olvasó rendszerek már léteznek, de a címlapokat egyelőre kevésbé egységesítették és több variációt mutatnak. 4
Irodalom
* A katalógussal való behasonlítás révén persze megoldható a probléma. (A szerk.)
![]()
|
Országos Széchényi Könyvtár Észrevételek (2000/04/12) |